Data Practices for Open Science
About Me
- Albury C
- MSc, Marine microbial trace nutrient dynamics, Dalhousie University
- Currently a data scientist for Infrastruture Canada

About You

FAIR Principles
- “Importantly, it is our intent that the principles apply not only to ‘data’ in the conventional sense, but also to the algorithms, tools, and workflows that led to that data.” (Wilkinson et al. 2016)
- Focus on machine actionability

Documentation: Use version control
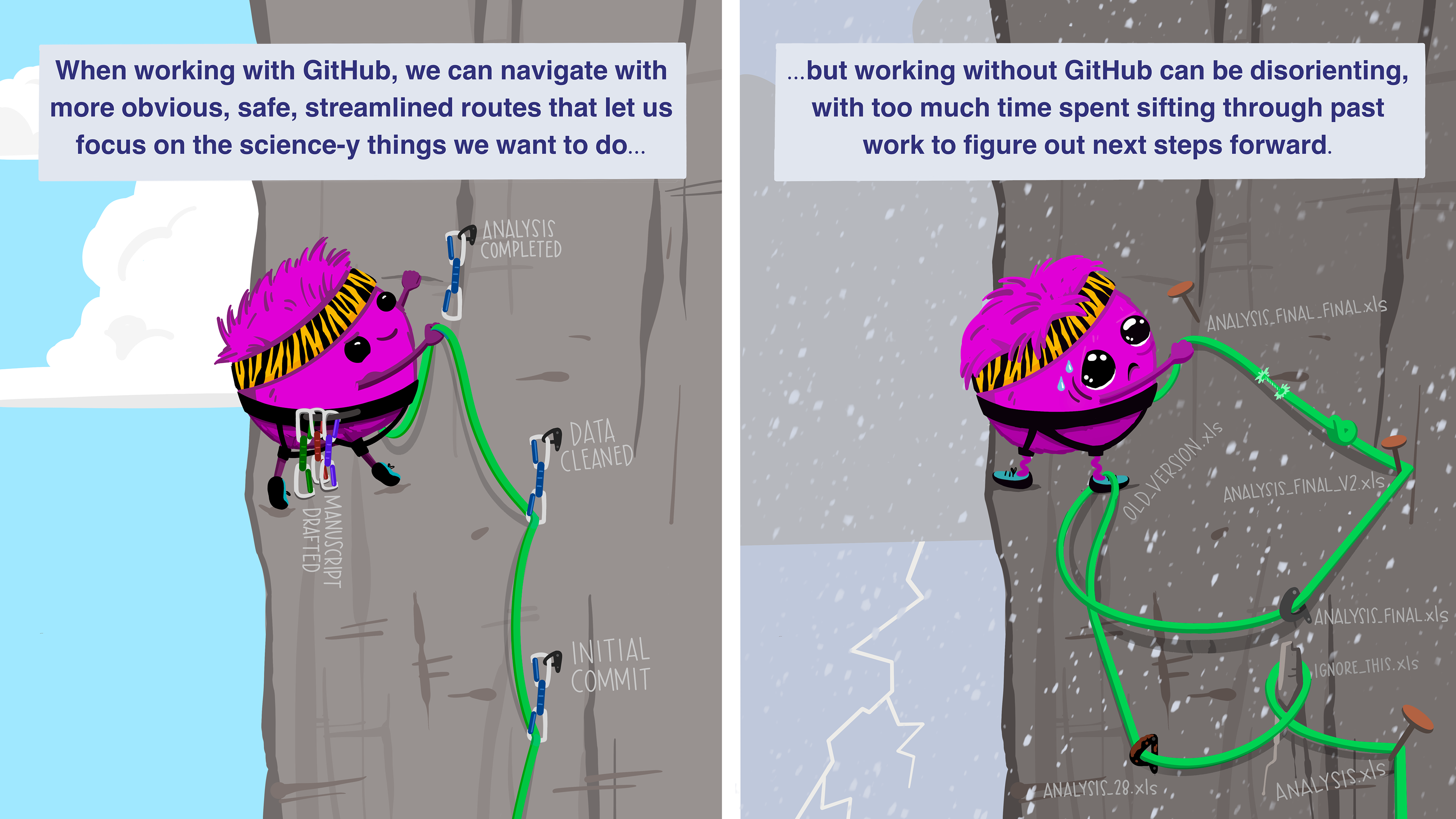
Illustration by Allison Horst
Storing Your Data: Use tidy data format

Illustration from Tidy Data for reproducibility, efficiency, and collaboration by Julia Lowndes and Allison Horst
Storing Your Data: Redundancy in data is good
- This table contains two types of observations: song information and Billboard ranking (Wickam 2014)
- One entry each week the song remains on the Billboard top 100
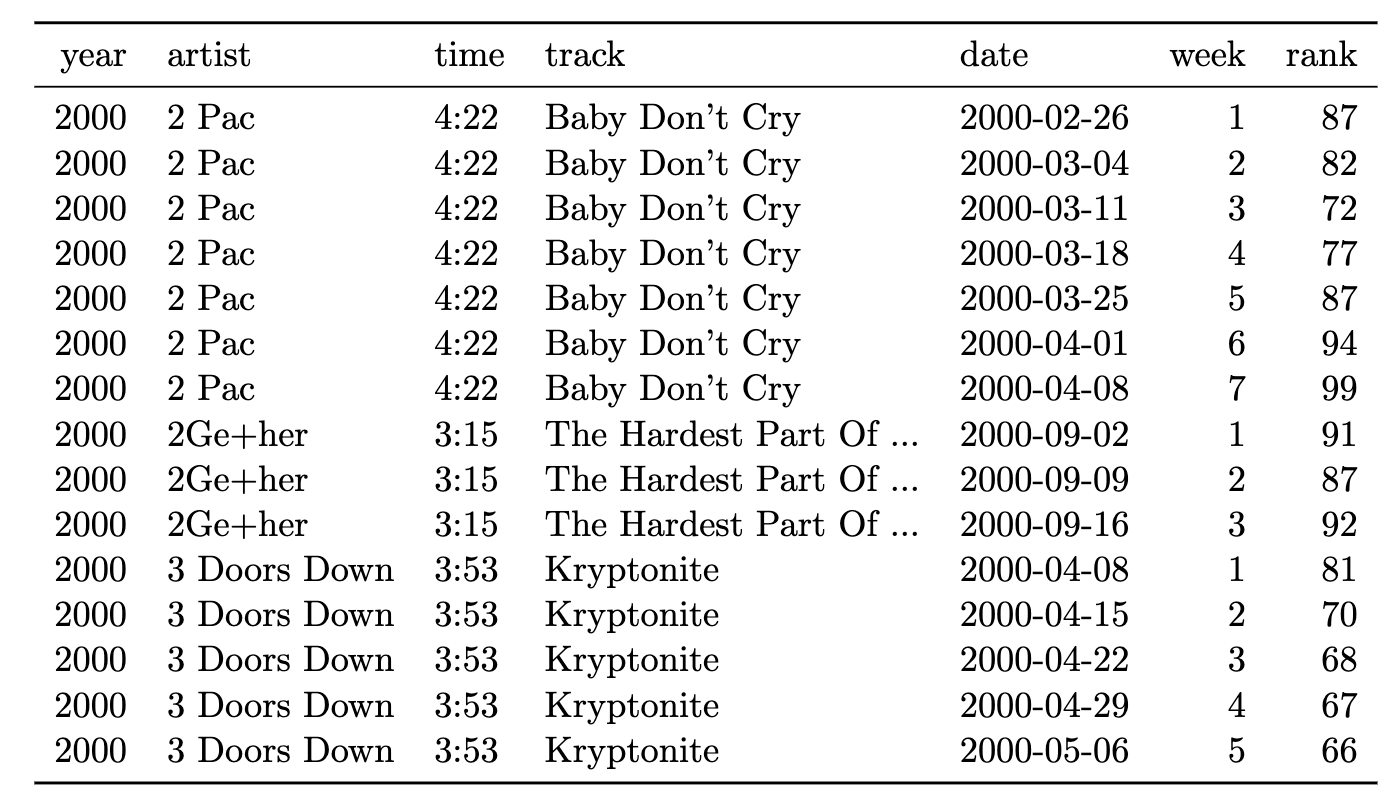
Storing Your Data: Redundancy in data is good
Instead, they should be saved as:
- a table with song’s artists, names and run times
- a table with details on their Billboard ranking (Wickam 2014).
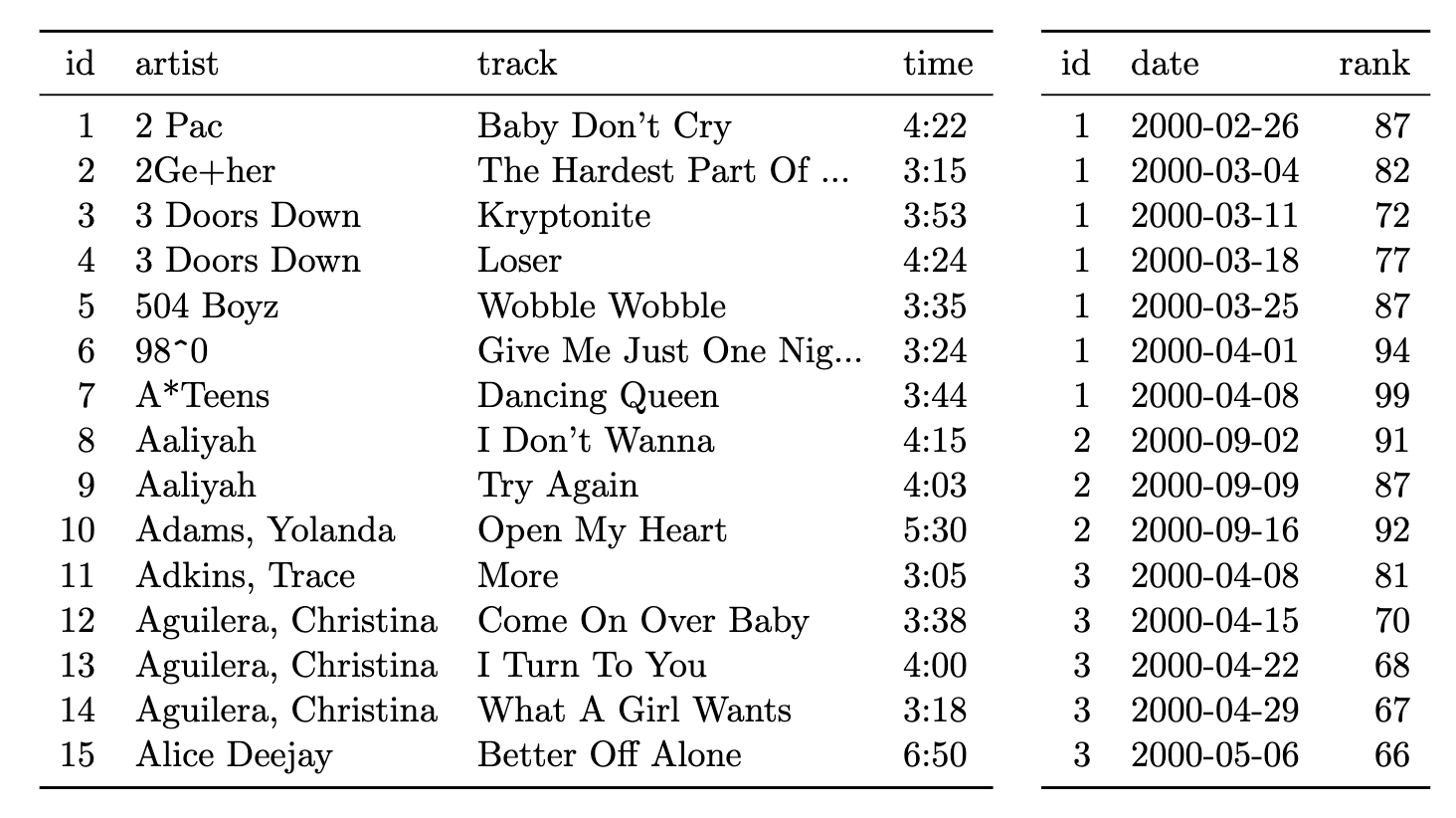
Storing Your Data: Redundancy in data is good
- Reduces each table to only one type of observation, avoiding confusion
- Saves space